作者: 龙心尘&&寒小阳
时间:2015年12月。
出处:
声明:版权所有,转载请联系作者并注明出处,谢谢。
“机器学习”是一个很实践的过程。就像刚开始学游泳,你在只在岸上比划一堆规定动作还不如先跳到水里熟悉水性学习来得快。以我们学习“机器学习”的经验来看,很多高大上的概念刚开始不懂也没关系,先写个东西来跑跑,有个感觉了之后再学习那些概念和理论就快多了。如果别人已经做好了轮子,直接拿过来用则更快。因此,本文直接用Michael Nielsen先生的代码(github地址,压缩包地址)作为例子,给大家展现神经网络分析的普遍过程:导入数据,训练模型,优化模型,启发式理解等。
本文假设大家已经了解python的基本语法,并在自己机器上运行过简单python脚本。
二、 我们要解决的问题:手写数字识别手写数字识别是机器学习领域中一个经典的问题,是一个看似对人类很简单却对程序十分复杂的问题。很多早期的验证码就是利用这个特点来区分人类和程序行为的,当然此处就不提12306近乎反人类的奇葩验证码了。

回到手写数字识别,比如我们要识别出一个手写的“9”,人类可能通过识别“上半部分一个圆圈,右下方引出一条竖线”就能进行判断。但用程序表达就似乎很困难了,你需要考虑非常多的描述方式,考虑非常多的特殊情况,最终发现程序写得非常复杂而且效果不好。
而用(机器学习)神经网络的方法,则提供了另一个思路:获取大量的手写数字的图像,并且已知它们表示的是哪个数字,以此为训练样本集合,自动生成一套模型(如神经网络的对应程序),依靠它来识别新的手写数字。

本文中采用的数据集就是著名的“MNIST数据集”。它的收集者之一是人工智能领域著名的科学家――Yann LeCu。这个数据集有60000个训练样本数据集和10000个测试用例。运用本文展示的单隐层神经网络,就可以达到96%的正确率。 三、 图解:解决问题的思路
我们可以用下图展示上面的粗略思路。

但是如何由“训练集”来“生成模型”呢?
在这里我们使用反复推荐的逆推法――假设这个模型已经生成了,它应该满足什么样的特性,再以此特性为条件反过来求出模型。
可以推想而知,被生成的模型应该对于训练集的区分效果非常好,也就是相应的训练误差非常低。比如有一个未知其相应权重和偏移的神经网络,而训练神经网络的过程就是逐步确定这些未知参数的过程,最终使得这些参数确定的模型在训练集上的误差达到最小值。我们将会设计一个数量指标衡量这个误差,如果训练误差没有达到最小,我们将继续调整参数,直到这个指标达到最小。但这样训练出来的模型我们仍无法保证它面对新的数据仍会有这样好的识别效果,就需要用测试集对模型进行考核,得出的测试结果作为对模型的评价。因此,上图就可以细化成下图:
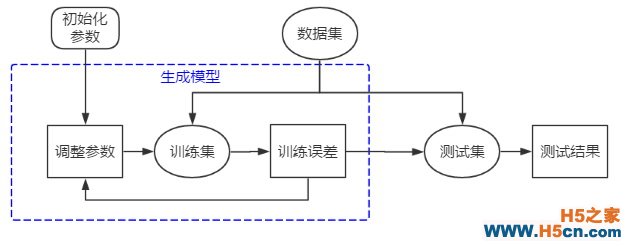
但是,如果我们已经生成了多个模型,怎么从中选出最好的模型?一个自然的思路就是通过比较不同模型在测试集上的误差,挑选出误差最小的模型。这个想法看似没什么问题,但是随着你测试的模型增多,你会觉得用测试集筛选出来的模型也不那么可信。比如我们增加一个神经网络的隐藏层节点,就会产生新的对应权重,产生一个新的模型。但是我也不知道增加多少个节点是合适的,所以比较全面的想法就是尝试测试不同的节点数x∈(1,2,3,4,…,100), 来观察这些不同模型的测试误差,并挑出误差最小的模型。这时我们发现我们的模型其实多出来了一个参数x, 我们挑选模型的过程就是确定最优化的参数x 的过程。这个分析过程与上面训练参数的思路如出一辙!只是这个过程是基于同一个测试集,而不训练集。那么,不同的神经网络的层数是不是也是一个新的参数y∈(1,2,3,4,…,100), 也要经过这么个过程来“训练”?
我们会发现我们之前生成模型过程中很多不变的部分其实都是可以变换调节的,这些也是新的参数,比如训练次数、梯度下降过程的步长、规范化参数、学习回合数、minibatch 值等等,我们把他们叫做超参数。超参数是影响所求参数最终取值的参数,是机器学习模型里面的框架参数,可以理解成参数的参数,它们通常是手工设定,不断试错调整的,或者对一系列穷举出来的参数组合一通进行枚举(网格搜索)来确定。但无论如何,这也是基于同样一个数据集反复验证优化的结果。在这个数据集上最后的结果并不一定在新的数据继续有效。所以为了评估这个模型的识别效果,就需要用新的测试集对模型进行考核,得出的测试结果作为对模型的评价。这个新的测试集我们就直接叫“测试集”,之前那个用于筛选超参数的测试集,我们就叫做“交叉验证集”。筛选模型的过程其实就是交叉验证的过程。
所以,规范的方法的是将数据集拆分成三个集合:训练集、交叉验证集、测试集,然后依次训练参数、超参数,最终得到最优的模型。
因此,上图可以进一步细化成下图:

或者下图:

可见机器学习过程是一个反复迭代不断优化的过程。其中很大一部分工作是在调整参数和超参数。
四、 先跑跑再说:初步运行代码Michael Nielsen的代码封装得很好,只需以下5行命令就可以生成神经网络并测试结果,并达到94.76%的正确率!。
import mnist_loader import network # 将数据集拆分成三个集合:训练集、交叉验证集、测试集 training_data, validation_data, test_data = mnist_loader.load_data_wrapper() # 生成神经网络对象,神经网络结构为三层,每层节点数依次为(784, 30, 10) net = network.Network([784, 30, 10]) # 用(mini-batch)梯度下降法训练神经网络(权重与偏移),并生成测试结果。 # 训练回合数=30, 用于随机梯度下降法的最小样本数=10,学习率=3.0 net.SGD(training_data, 30, 10, 3.0, test_data=test_data)本文并不打算详细解释随机梯度下降法的细节,感兴趣的同学请阅读前文《深度学习与计算机视觉系列(4)_最优化与随机梯度下降》
 相关文章
相关文章



 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
