用python 10min手写一个简易的实时内存监控系统
简易的内存监控系统
本文需要有一定的python和前端基础,如果没基础的,请关注我后续的基础教程系列博客
文章github源地址,还可以看到具体的代码,喜欢请在原链接右上角加个star
腾讯视频链接录制中间网出问题了,重启了一下,所以有两部分
本文的目的在于,尽可能用简单的代码,让大家了解内存监控的原理 主题思路
思路图
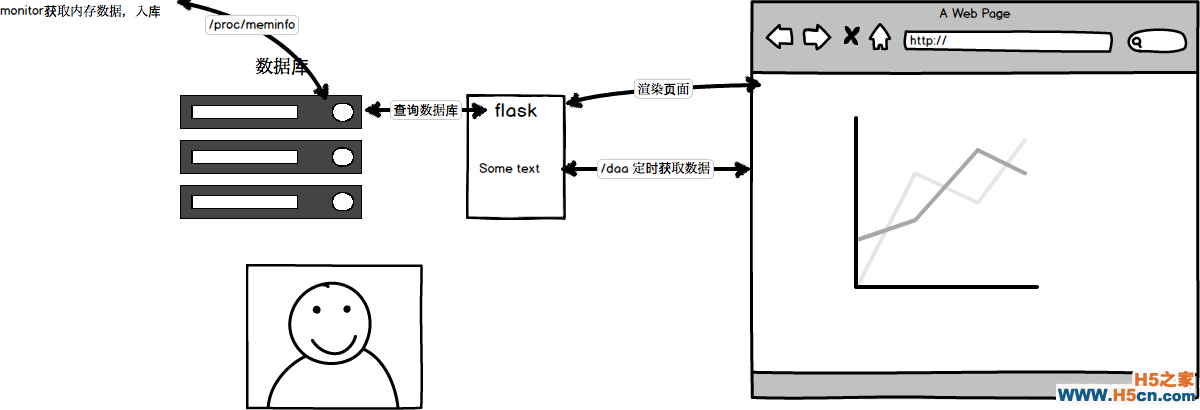
其实所有的监控项,包括内存数据,都是从文件中读取的,大家执行以下 cat /proc/meminfo就可以看到关于内存的信息,我们关注的是前四行,总内存,空闲内存,缓冲和缓存大小
计算内存占用量公式:
(总内存-空闲内存-缓冲-缓存)/1024Mb
代码呼之欲出 monitor.py
用with打开文件,可以自动关闭,比直接open优雅那么一丢丢
def getMem(): with open('/proc/meminfo') as f: total = int(f.readline().split()[1]) free = int(f.readline().split()[1]) buffers = int(f.readline().split()[1]) cache = int(f.readline().split()[1]) mem_use = total-free-buffers-cache print mem_use/1024 while True: time.sleep(1) getMem()执行文件 python monitor.py,每一秒打印一条内存信息
[woniu@teach memory]$ python mointor.py 2920 2919 2919 2919 2919我们可以写个很搓的测试代码,占用一点内存,看看数据会不会变 执行下面代码,能看到内存使用量明显多了几M
# test.py s = 'akdsakjhdjkashdjkhasjkdhasjkdhkjashdaskjhfoopnnm,ioqouiew'*100000 for i in s: for j in s: s.count(j)获取内存数据done!
第二步存储数据库 我们选用mysql新建表格,我们需要两个字段,内存和时间 sql呼之欲出,简单粗暴
create memory(memory int,time int)我们的 monitor.py就不能只打印内存信息了,要存储数据库啦,引入mysql模块,代码如下
import time import MySQLdb as mysql db = mysql.connect(user="reboot",passwd="reboot123",db="memory",host="localhost") db.autocommit(True) cur = db.cursor() def getMem(): with open('/proc/meminfo') as f: total = int(f.readline().split()[1]) free = int(f.readline().split()[1]) buffers = int(f.readline().split()[1]) cache = int(f.readline().split()[1]) mem_use = total-free-buffers-cache t = int(time.time()) sql = 'insert into memory (memory,time) value (%s,%s)'%(mem_use/1024,t) cur.execute(sql) print mem_use/1024 #print 'ok' while True: time.sleep(1) getMem()比之前的多了拼接sql和执行的步骤,具体过程见视频,大家到数据库里执行一下下面的sql,就能看到我们辛辛苦苦获取的内存数据啦
select * from memory我们的数据库里数据越来越多,怎么展示呢
我们需要flask 我们看下文件结构
. ├── flask_web.py web后端代码 ├── mointor.py 监控数据获取 ├── static 静态文件,第三方图表库 │ ├── exporting.js │ ├── highstock.js │ └── jquery.js ├── templates │ └── index.html 展示前端页面 └── test.py 占用内存的测试代码flask_web就是我们的web服务代码,template下面的html,就是前端展示的文件,static下面是第三方库
flask_web的代码如下
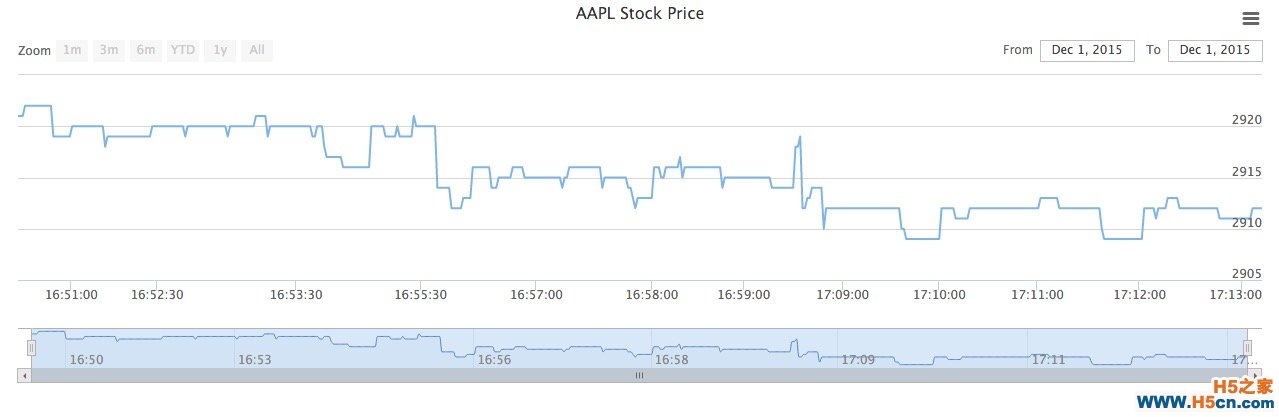
前端index.html highstock的demo页面,copy过来,具体过程见视频
<html> <head> <title>51reboot</title> </head> <body> hello world <div id="container" style="height: 400px; min-width: 310px"></div> <script src='/static/jquery.js'></script> <script src='/static/highstock.js'></script> <script src='/static/exporting.js'></script> <script> $(function () { // 使用当前时区,否则东八区会差八个小时 Highcharts.setOptions({ global: { useUTC: false } }); $.getJSON('/data', function (data) { // Create the chart $('#container').highcharts('StockChart', { rangeSelector : { selected : 1 }, title : { text : '内存数据' }, series : [{ name : '本机内存', data : data, tooltip: { valueDecimals: 2 } }] }); }); }); </script> </body> </html>具体观察数据结构的过程,见视频和demo链接,我们做的 就是把数据库里的数据,拼接成前端画图需要的数据,展现出来
这时候前端就能看到图表啦
python
tmp_time = 0 @app.route('/data') def data(): global tmp_time if tmp_time>0: sql = 'select * from memory where time>%s' % (tmp_time/1000) else: sql = 'select * from memory' cur.execute(sql) arr = [] for i in cur.fetchall(): arr.append([i[1]*1000,i[0]]) if len(arr)>0: tmp_time = arr[-1][0] return json.dumps(arr)
 相关文章
相关文章

 精彩导读
精彩导读 热门资讯
热门资讯 关注我们
关注我们
